
自社で開発した数多くのAIプロダクトをオープンソースとして提供してきたUberですが、2020年のスタートとともにまたひとつ新しいAIソフトウェアをオープンソースとして公開しました。モデルの精度とパフォーマンスを向上させる、モデル非依存(model-agnostic)なビジュアルデバッグツール「Manifold」が「Manifold」が1月7日付けでApache 2.0 Licenseのもとで公開されています。
- 【Uber Engineering】Open Sourcing Manifold, a Visual Debugging Tool for Machine Learning
- 【GitHub】Manifold
Manifoldはもともと、2019年1月からUberがインハウスで開発してきたツールで、同じくUberが開発するマシンラーニングプラットフォーム「Michelangelo」の機能の一部として提供されてきました。Michelangeloをはじめ、UberのAIプロダクトはどれも透明性を非常に重要視しており、モデルの挙動や予測の根拠をユーザが理解しやすいかたちで提供することに注力していますが、複数のモデルのパフォーマンスを可視化し、モデルの劣化要因を特定しやすくするManifoldは、そうしたUberのブラックボックス化を回避する姿勢を象徴するツールだといえます。
今回リリースされた「Manifold version 1」では以下の2つのビューが提供されます。
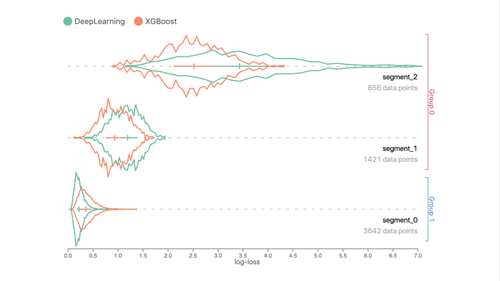
- Performance Comparison View … 1つのデータセットを複数のデータセグメントに自動的に分割し、それぞれを複数のモデルにインプットして、パフォーマンスの違いを可視化する。LogLossなど一般的な二値分類をサポート
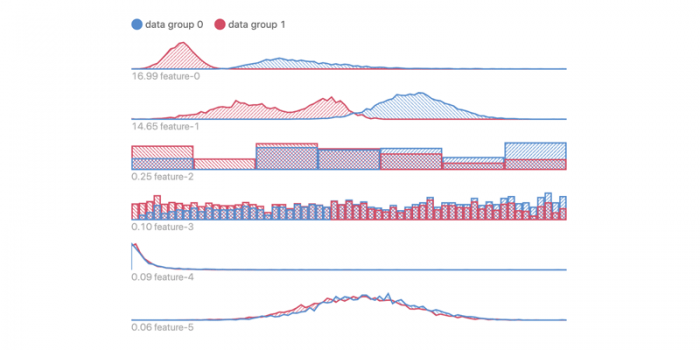
- Feature Attribution View … データグループ(セグメント)ごとの特徴量分布を可視化し、予測の誤判定に影響する部分を特定する。特徴量として数値やカテゴリカルといった表形式データに加え、地理空間データもサポート
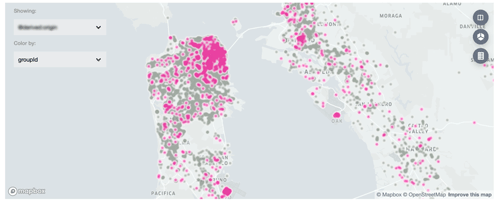
ManifoldはJupyter Notebookと統合できるため、Pythonライブラリ「Pandas」のDataFrameから取り込んだオブジェクトを扱うことも可能です。また、インスタンスごと、あるいは特徴量ごとのデータスライシングが動的に行えるため、パフォーマンスの比較がしやすい点も特徴のひとつです。今後はnpmパッケージパージョンやPythonパッケージバージョンの提供も予定されているとのことで、さらに使いやすさが向上することが期待されます。
0